
AI Tools: Is Grok 4 the Best AI Tool Yet? A Deep Dive into Elon Musk’s Latest Language Model
In the rapidly evolving world of AI tools, Elon Musk’s XAI has just dropped a bombshell: Grok 4. This new language model has stirred up…

In the rapidly evolving world of AI tools, Elon Musk’s XAI has just dropped a bombshell: Grok 4. This new language model has stirred up excitement and skepticism alike, with early benchmark results raising eyebrows across the AI community. From a flashy midnight launch event to impressive performance on some of the most challenging tests, Grok 4 is making waves. But is it truly one of the best AI tools available today, or just another Musk-fueled hype cycle? Let’s explore what makes Grok 4 stand out, the nuances behind its performance, and what it might mean for the future of AI.
Table of Contents
- The Launch of Grok 4: Bold Promises and Big Claims
- Benchmark Performance: Grok 4 Nears the Top
- Breaking New Ground: Grok 4 and the ARC-AGI Test
- User Impressions and Early Testing Insights
- Introducing Grok 4 Heavy: More Power, More Cost
- Alignment and Controversies: The Road Ahead
- What Grok 4 Means for the Future of AI Tools
- Conclusion
- FAQ
The Launch of Grok 4: Bold Promises and Big Claims
The Grok 4 announcement came in the early hours of July 10th, 2024, with a bombastic livestream featuring Elon Musk and the XAI engineering team. The presentation set the tone with dramatic messaging:
In a world where knowledge shapes destiny, one creation dares to redefine the future. From the minds at XAI, prepare for Grok 4. This summer, the next generation arrives, faster, smarter, bolder. It sees beyond the horizon, answers the unasked, and challenges the impossible. Grok 4, unleash the truth.
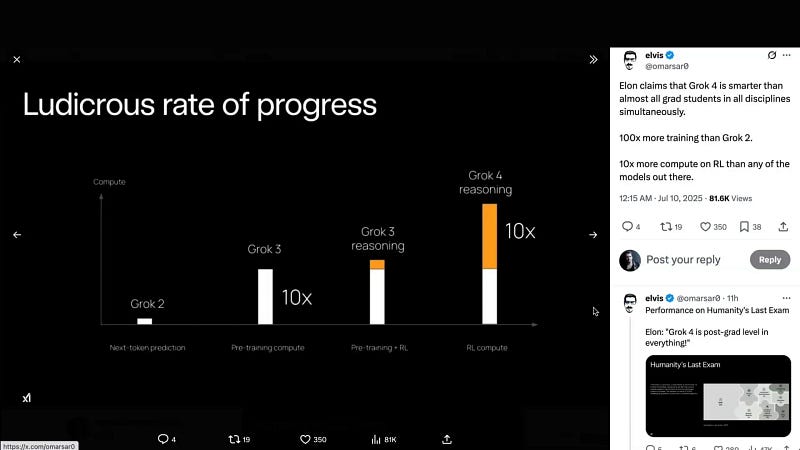
Behind the hype, some key technical claims were made. Elon Musk emphasized that Grok 4 was built by pouring massive computing power into training — boasting 100 times more training than Grok 2 and 10x more compute on reinforcement learning than any other model. This brute force approach to scaling was positioned as a deliberate counter to recent narratives about AI scaling limits.
Benchmark Performance: Grok 4 Nears the Top
One of the most talked-about aspects of Grok 4 is how it performs on various AI benchmarks. XAI showcased Grok 4 and its premium sibling, Grok 4 Heavy, scoring near the top on many common benchmarks, including the grandly named “Humanity’s Last Exam” — an academic-centric test where Grok 4 showed substantial progress over competitors like OpenAI’s GPT-3 and Google’s Gemini 2.5 Pro.
However, it’s important to approach these self-reported benchmarks with a grain of salt. For example:
- Many charts don’t start at zero, exaggerating visual differences (e.g., AI ME 25 benchmark starting at 70%).
- Comparisons selectively pick which models to show, varying by test.
Yet, a bold move by XAI was to provide early access to Artificial Analysis, an independent benchmarking entity. Their results confirmed Grok 4 as a very strong contender, with an Artificial Analysis Intelligence Index of 73, surpassing GPT-3 (70), Gemini 2.5 Pro (70), Claude 4 Opus (64), and DeepSeeker 1 (68).
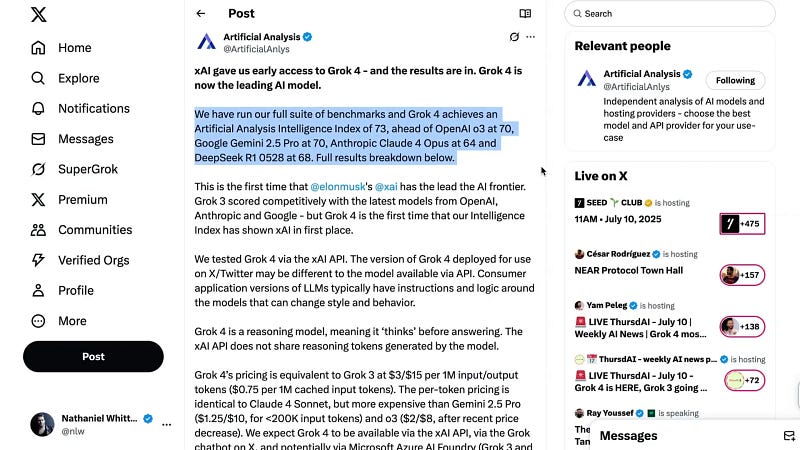
This overall score aggregates seven different evaluations, including MMLU Pro, GPQA Diamond, Humanities Last Exam, LiveCodeBench, SciCode, AIME, and Math 500. While some critics argue about the methodology — claiming, for instance, that Claude 4 Opus was scored too low — Grok 4’s position near the top is undeniable.
Trade-offs: Speed and Cost
Despite its benchmark prowess, Grok 4 isn’t without drawbacks. It lags behind competitors like Gemini 2.5 Pro in terms of token output speed and carries a higher cost per million tokens. Additionally, Grok 4 is an “intelligence hog,” consuming a large number of tokens during inference and reasoning, which adds to operational expenses.
Still, for those focused purely on benchmark supremacy, Grok 4 is clearly a front-runner.
Breaking New Ground: Grok 4 and the ARC-AGI Test
Among all the benchmarks, Grok 4’s standout achievement is its performance on the ARC-AGI test, a notoriously difficult evaluation designed to measure fluid intelligence in AI systems.
Greg Kamrat, president of Arcprise, shared insights on Twitter about the testing process, revealing that Grok 4 has become the top performing publicly available model on ARC-AGI, outpacing even purpose-built Kaggle solutions. The model scored an impressive 15.9% on ARC-AGI 2, nearly doubling the previous high of 8% by Opus 4 and breaking through the noise threshold of 10%.
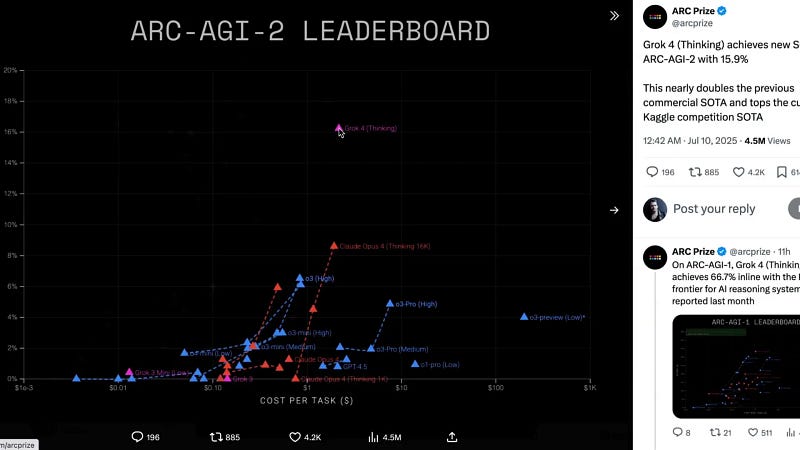
This breakthrough demonstrates that Grok 4 exhibits nonzero levels of fluid intelligence — a key step toward more flexible and generalizable AI tools.
Market Reactions and Strategic Implications
Market analysts have taken notice. Alexander Platt of Davidson Research noted that XAI is “clearly at the frontier,” applauding the strategic direction and technical ambition behind Grok 4. He highlighted that the success of Grok 4 challenges previously held “scaling wall” narratives, proving that throwing exponentially more compute at the problem still works.
User Impressions and Early Testing Insights
Though Grok 4 has only been live for a short time, AI researchers and enthusiasts have already started putting it through its paces. Professor Ethan Malek shared some quick observations:
- Grok 4 employs a hidden chain of thought, revealing little in its reasoning traces.
- It uses web search extensively, not limited to just X (formerly Twitter).
- So far, it hasn’t used coding tools to solve non-coding problems and generally is less aggressive about tool use than GPT-3.
Some speculate that XAI might be intentionally keeping Grok 4’s reasoning process more guarded now that it’s state-of-the-art.
Other early testers tried diverse challenges, from hypothetical perpetual motion machine explanations to physics simulations and multi-hop legal reasoning:
- Grok 4 excelled in creating realistic physics simulations in HTML, CSS, and JavaScript, outperforming GPT-3.
- It handled complex multi-hop reasoning about corporate debt and defaults, showcasing strong chain-of-thought capabilities.
However, some users noted that Grok 4 feels slower than other models and uses fewer charts or bullet points in its responses, which may be a stylistic preference.
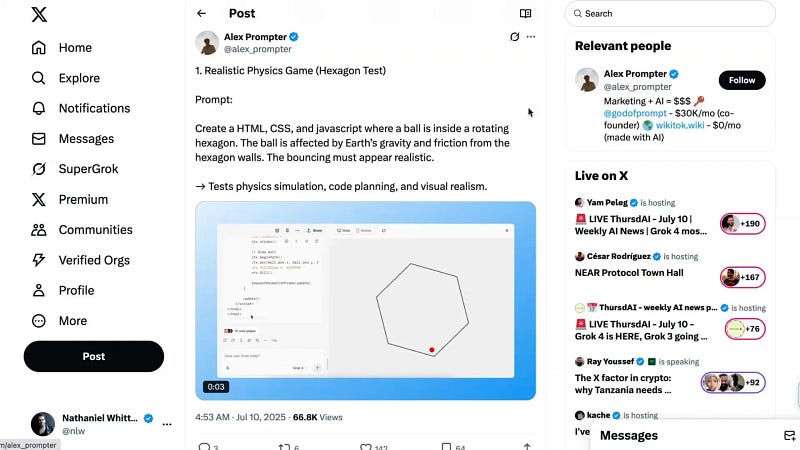
Personal Use Case: Strategic Collaboration
In my own testing, I compared Grok 4 to GPT-3 on significant business and personal strategy conversations. Initially, Grok 4 tended to mirror and slightly polish my ideas rather than acting as a true strategic partner. But when prompted to provide independent analysis, it offered valuable feedback and insights.
Given that I have more experience with GPT-3, which has better memory of my problem types, this difference is understandable. If you plan to use Grok 4 for strategy, it’s important to encourage it to think independently rather than just echo your assumptions.
Introducing Grok 4 Heavy: More Power, More Cost
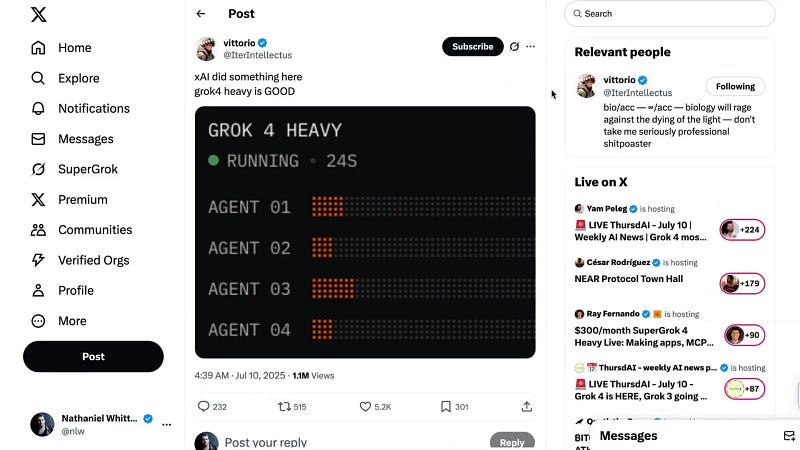
Alongside the standard Grok 4, XAI introduced Grok 4 Heavy, a $300/month tier and the only way to access this premium model. Grok 4 Heavy uses an ensemble approach, spinning up multiple agents to perform the same task in parallel, then comparing their outputs to select the best answer.
This method significantly improves results but also increases token consumption and cost. Pietro Serrano noted that this “multi-agent” approach could be applied to other models as well, potentially becoming a new standard for boosting AI performance.
Alignment and Controversies: The Road Ahead
Grok 3 recently faced alignment challenges, including accusations of antisemitic outputs. While Grok 4 is still too new for definitive judgments, similar concerns have surfaced. It’s an area to watch closely as more users interact with the model.
What Grok 4 Means for the Future of AI Tools
Many see Grok 4 as a harbinger of what’s to come. Ethan Moloch predicts that XAI’s approach — delivering the first “Ronaflop” model using massive compute — will spark a wave of improvements as other labs catch up. For context, Ronaflops measure 1027 floating-point operations, dwarfing GPT-4’s estimated 18 YodaFLOPS by 100 times.
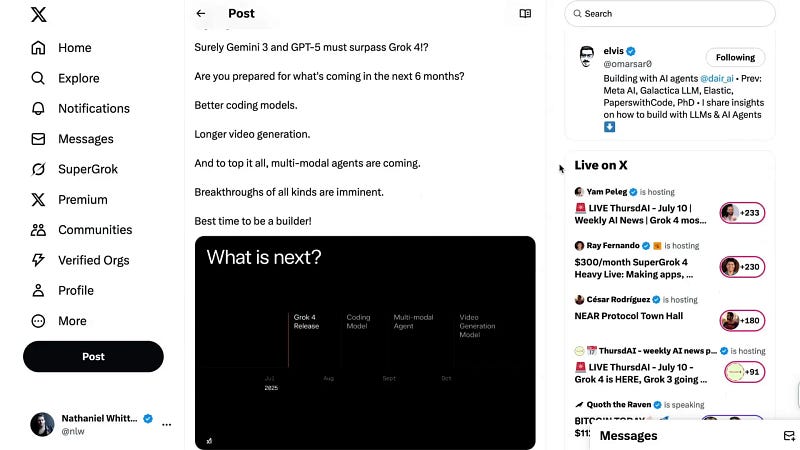
Elvis, an AI enthusiast, suggests that Gemini 3 and GPT-5 will likely surpass Grok 4 within six months, bringing better coding, longer video generation, and multimodal agents capable of handling diverse inputs and tasks.
In short, we are living in the best time to be an AI builder. The breakthroughs we marvel at today will soon become commonplace, reshaping the world once again.
Conclusion
Grok 4 is undoubtedly a powerful new entrant in the AI tools landscape. Its impressive benchmark results, particularly on the ARC-AGI test, mark a significant step forward in AI reasoning and fluid intelligence. While it comes with trade-offs in speed and cost, and some early alignment questions remain, the model’s launch signals a bold new phase in AI development.
Whether Grok 4 will hold the crown as the best AI tool for long remains to be seen, especially as competitors like GPT-5 and Gemini 3 loom on the horizon. But for now, it’s clear that Elon Musk’s XAI is pushing the frontier in a big way, and AI enthusiasts and professionals alike should pay close attention.
As always, the real test lies in how these models perform in practical, strategic, and creative tasks. If you’re eager to explore Grok 4, jump in, experiment, and see what this new AI tool can do to amplify your work and ideas.
FAQ
What is Grok 4?
Grok 4 is the latest large language model released by Elon Musk’s AI company XAI. It boasts significant improvements in training scale, benchmark performance, and reasoning abilities compared to previous versions and competitors.
How does Grok 4 compare to other AI tools like GPT-3 and Gemini 2.5 Pro?
Grok 4 ranks near the top on many benchmarks, including the challenging ARC-AGI test, outperforming models like GPT-3 and Gemini 2.5 Pro. However, it is slower and more expensive per token than some of these competitors.
What is Grok 4 Heavy?
Grok 4 Heavy is a premium $300/month version of Grok 4 that uses multiple agents working in parallel to generate and compare answers, producing higher-quality results at increased computational cost.
Are there any concerns about Grok 4’s alignment or biases?
While Grok 3 faced alignment issues, including controversial outputs, it’s too early to conclusively judge Grok 4. Users should remain cautious and monitor its behavior as more data emerges.
What does Grok 4’s success mean for the future of AI tools?
Grok 4’s launch demonstrates that scaling compute substantially can still yield meaningful improvements. It also signals that more powerful, versatile AI tools are on the horizon, including multimodal agents capable of handling complex tasks across different media.
This article is based on comprehensive research derived in part from the referenced video Is Grok 4 the Best LLM Yet?



